 آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی
آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی

آزمون F تحلیل واریانس یک طرفه یا ANOVA
آزمون ANOVA یا تحلیل واریانس یک طرفه برای آزمون مقایسه میانگین یک متغیر کمی در بین بیش از دو گروه مستقل استفاده می شود. در حقیقت این آزمون تعمیم یافته همان آزمون T دو نمونه مستقل است و دارای همان پیش فرض ها می باشد و تنها تفاوت این است که میانگین متغیر های کمی در بیش از دو گروه مستقل با هم مقایسه می شوند(مرادی، 1395)
در مثال مقاله قبل سازه عوامل استرس زا در آزمون t با دو نمونه مستقل در بین دو گروه مستقل دانشجویان آقا و خانم مورد مقایسه میانگین قرار گرفت. حال فرض کنید قرار است همین سازه در یک متغیر اسمی بیش از دو وجه مورد مقایسه قرار گیرد. مثلا در این سازه در بین دانشجویان 4 دانشکده مورد مقایسه میانگین قرار گیرد.
پیش فرض های آزمون تحلیل واریانس ANOVA
الف) متغیری که میانگین آن در چند گروه مستقل مقایسه می شود باید کمی باشد(یعنی مقیاس آن فاصله ای یا نسبی باشد)
ب) مقیاس متغیری که در آن مقایسه انجام می شود باید کیفی و در سطح اسمی(چند وجهی) باشد.
ج) متغیری که در آن مقایسه میانگین انجام می شود باید مستقل و از چند جمعیت متفاوت باشند.
د) توزیع داده های متغیری که میانگین آن در چند گروه مستقل مقایسه می شود باید نرمال باشد.(مرادی، 1395)
بنابراین در این تحقیق فرضیه ای به صورت زیر قرار دارد:
«متغیر عوامل ایجاد کننده استرس در بین دانشجویان دانشکده های مختلف تفاوت دارد.»
شرط اول) سازه عوامل ایجاد کننده استرس متغیری کمی است زیرا این سازه توسط چندین شاخص اندازه گیری شده است و ما این شاخص ها را توسط عملیات compute به یک ستون در نرم افزار spss تبدیل کرده ایم. بنابراین شرط اول برقرار است.
شرط دوم) دانشکده های مختلف متغیری اسمی(کیفی) و چند وجهی شامل دانشکده ادبیات، علوم پایه، کشاورزی و فنی مهندسی است بنابراین شرط دوم برقرار است.
شرط سوم) همچنین دانشجویان این دانشکده های مختلف از یکدیگر مستقل هستند که منجر به تایید شرط سوم می شود.
شرط چهارم) در بخش پیش پردازش ها شکل توزیع متغیر های پژوهش بررسی شده است که نشان می دهد توزیع داده های این متغیر ها نرمال هستند بنابراین پیش شرط چهارم برای انجام آزمون تحلیل واریانس ANOVA برقرار است. ( توجه شود که پیش تست نرمال بودن توزیع داده های سازه عوامل ایجاد کننده استرس باید حتما توسط آزمون چولگی و کشیدگی سنجیده شود. پیرامون این موضوع در مقالات گذشته و کتاب های قرار داده شده در سایت بحث های کاملی انجام شده است)
باید ذکر کرد که آزمون تحلیل واریانس ANOVA تنها به این سوال پاسخ می دهد که آیا بین گروه های مختلف مستقل تفاوت میانگین(متغیر کمی) وجود دارد یا ندارد؟ یعنی از کیفیت تفاوت میانگین اطلاعاتی به ما نمی دهد. (کیفیت تفاوت یعنی اینکه بیان کند بین کدام گروه ها تفاوت وجود دارد)
بنابراین برای رفع این مشکل باید از آزمون های تعقیبی مناسب استفاده نماییم. این آزمون های مکمل را Post hoc می خوانند و محققین عزیز باید بر اساس آزمون لوین که تعیین می کند آیا واریانس های گروه های مستقل برابر هستند یا خیر دست به انتخاب یک آزمون تعقیبی مناسب برای پژوهش خود بزنیم.
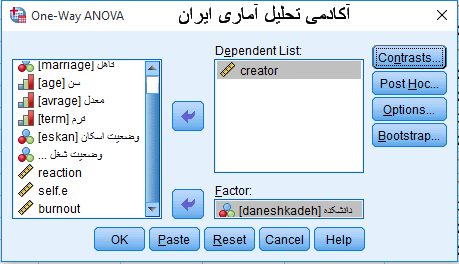
ابتدا از آدرس زیر به سراغ اجرای آزمون تحلیل واریانس یک طرفه می رویم.
Analyze > Compare Mean > One-Way ANOVA
در پنجره دیالوگ باز شده متغیر کمی که می خواهیم دست به مقایسه میانگین آن در گروه های مختلف بزنیم را به سمت راست منتقل کرده و سپس متغیر کیفی(اسمی) را وارد قسمت FACTOR می کنیم. سپس از قسمت Option باید تیک گزینه Homogeneity of variance test را بزنیم. این در حقیقت همان آزمون لوین برای تشخیص برابری یا عدم برابری واریانس ها در گروه های مختلف متغیر اسمی دانشکده های مختلف است. continue را می زنیم و در نهایت در پنجره اول ok را می زنیم(فعلا به سراغ انتخاب آزمون تعقیبی نمی رویم چون باید ابتدا دو سوال پاسخ داده شود.
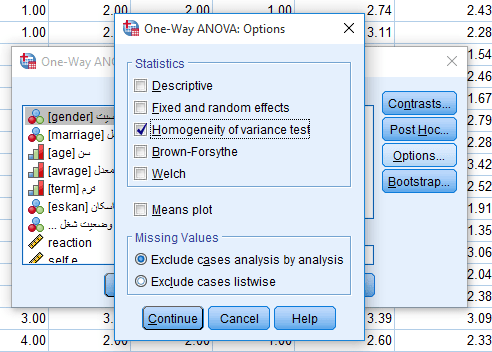
- آیا واریانس ها در گروه ها برابر هستند یا خیر؟(آزمون لوین)
- آیا بین گروه های مختلف تفاوت وجود دارد یا خیر ؟
پاسخ به سوال اول را آزمونی به نام آزمون لوین به شما خواهد داد. آزمون لوین آزمونی برای تشخیص برابری و عدم برابری واریانس ها است. یعنی فرض آماری آن به صورت زیر می باشد:
واریانس های دو گروه با هم برابر هستند H0:
واریانس های دو گروه با هم برابر نیستند H1:
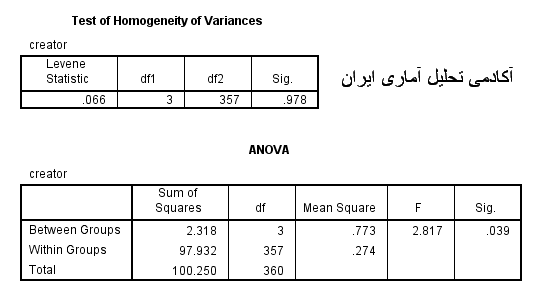
با توجه به نتایج آزمون لوین مشخص است که سطح معناداری(sig) بالاتر از مقدار 0.05 است یعنی فرض H1 رد و فرض H0 پذیرفته می شود. بنابراین واریانس گروه های مستقل دانشجویان دانشکده های مختلف در سازه عوامل استرس زا با هم برابر هستند.
بنابراین باید آزمون های تعقیبی از بین آزمون هایی با پیش شرط برابری واریانس ها انتخاب گردد(این ایرادی است که متاسفانه در بسیاری از تحقیقات مشاهده می شود و محققین به صورت ناآگاهانه دست به انتخاب یکسری آزمون های معروف مثل توکی میزنند در صورتی که باید بدانند که تمام آن 14 آزمون تعقیبی در پنجره بالا و 4 آزمون تعقیبی در پنجره پایین هر کدام شروط خاص خود را برای انتخاب شدن دارند که تمام آن ها در کلاس های آکادمی تحلیل آماری ایران بحث می شود)
فرضیه مبنی بر اینکه «سازه عوامل ایجاد کننده استرس در بین دانشجویان دانشکده های مختلف تفاوت دارد» در نتیجه فرض آماری بصورت زیر تنظیم می شود.
H0: µ1= µ2= µ3= µ4
H1: حداقل در بین دو گروه میانگین ها تفاوت دارد
با توجه به اطلاعات مندرج در جدول ، ميتوان دريافت که بر اساس مقدار sig که کمتر از 0.05 است در سطح اطمینان 95 درصد فرض H0 رد و فرض H1 تایید می شود. یعنی سازه عوامل ایجاد کننده استرس در بین دانشجویان دانشکده های مختلف تفاوت دارد.
اما هنوز مشخص نیست که این تفاوت بین کدام گروه ها است. برای اندازه گیری این موضوع از آزمون تعقیبی LSD استفاده شده است(جدول بالا) که نسبت به حجم نمونه گروه های مختلف خنثی است و پیش شرط برابر بودن واریانس ها را دارد.
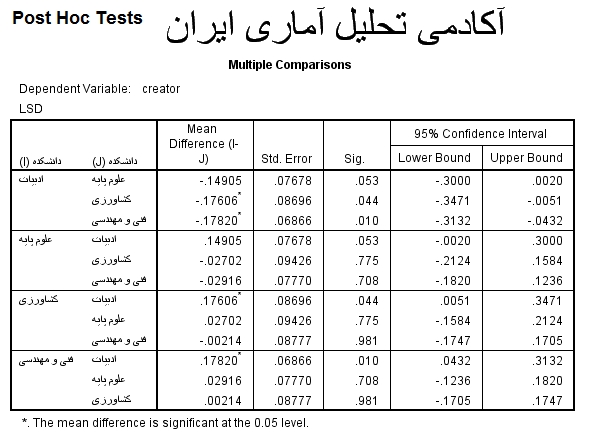
با توجه به نتایج آزمون تعقیبی بین دانشجویان دانشکده ادبیات و کشاورزی و نیز بین دانشجویان دانشکده ادبیات و فنی و مهندسی میانگین سازه عوامل ایجاد کننده استرس تفاوت معناداری دارد. اما بین سایر دانشگاه ها تفاوت میانگین معنادار نیست. همچنین با توجه به علامت حدود پایین و بالا، میانگین عوامل ایجاد کننده استرس هر دو دانشکده کشاورزی و فنی و مهندسی بزرگتر از دانشکده ادبیات است.
مقالات مرتبط مهم:
آزمون t با دو نمونه مستقل به زبان ساده
تحلیل واریانس چند متغیره یا Manova
فیلم آموزش تصویری سرچ با استراتژی علمی به همراه آموزش publish or perish
محسن مرادی
مطالب سایت و کانال انحصارا توسط این سایت تولید می شود و از استفاده آن بدون ذکر منبع سایت خودداری شود




سلام دکترجان …خیلی ممنون بابت مطالب مفید سایت ..وقتی بخواهیم از مطلب شما در پایان نامه استفاده کنیم چطوررفرنس بدیم رفرنس کامله (مرادی .1395)چی میشه؟؟
سلام این کتاب ها با ویرایش و ادیت جدید برای نمایشگاه کتاب میاد اما مطالب از این کتاب ها بوده
مرادی، محسن، 1394، مدل سازی معادلات ساختاری با استفاده از نرم افزار های ایموس، لیزرل و اسمارت پی ال اس، انتشارات تحلیل آماری ایران ، چاپ اول
مرادی، محسن، میر الماسی، آیدا، 1398 روش پژوهش عملگرا، انتشارات آکادمی تحلیل آماری ایران، چاپ دوم
خیلی متشکرم
سلام
ضمن تشکر لیست کتابهای موجود را کجا می تونم ببینم . ؟
در مطالب جدیدتر اطلاعات کتاب شناسی کتاب های خودمون بیان شده
سلام خسته نباشید.اگر در تست one way anova بحوایم پی ولیو رو بگیم بین همه گروه ها معنا دار باشه به طوری که پی ولیو کمتر از یک هزارم اما یک پی ولیو کمتر از پنج شدم باشه چه طور باید گزارش کنیم؟
در عرف نگارش باید pvalue یا sig در دنبا که در حقیقت خطای محقق برای تعمیم الگوهای کشف شده در نمونه به جامعه است باید با عدد 0.05 گزارش شود اما در ذهن باید کمتر از 0.01 را نیز محاسبه کرد. مثلا pvalue=.002 برای ضریب فیشر شده است. اکنون این مقدار را اینگونه تفسیر می کنیم. می گوییم از انجا که مقدار pvalue کمتر از 0.05 می باشد(اما در ذهن می بینیم کمتر از 0.01 هم هست) در سطح اطمینان 99 درصد فرض صفی رد و فرض محقق که خبر از تفاوت متغیر بین گروه های مختلف متغیر فاکتور است در جامعه آماری پژوهش تایید می شود.
سلام توی مثال بالا در قسمت اول فرض h1 پذیرفته و h0 رد شده بود. اما در قسمت post hoc توضیح دادید برای فرض های عکس چیزی هست که توی مثاله. یعنی post hoc بر ای h1 رد و h0 پذیرفته شده !!!! با همون فرض اول باید از چه آزمونی به جای LSD استفاده کنیم؟
نه عزیزم عکس نیست. در قسمت اول با آزمون آنووا مواجهه داریم که فقط وجود یا عدم وجود تفاوت رو بیان می کند. اما درباره کیفیت تفاوت یعنی اینکه بین کدوم گروه هاست و جهت اون ناتوان و عاجز است. بنابراین از آزمون های تعقیبی و مکمل استفاده می شود. اما اینکه چه آزمونی را انتخاب کنبم باید آزمون لوین بزنیم که زدیم. در نهایت مشخص شد از 14 آزمون تعقیبی اول باید انتخاب کنیم. اما حال کدوم یک از 14 آزمون. برای این مطلبی گذاشتم بنام نکات بسیار مهم آزمون های تعقیبی بخونش دلیلی انتخاب مشخص می شود.
سلام
به من گفتند که برای نمایش استقلال یا عدم استقلال دو متغیر که یکی کمی و دیگری طبقه ای است باید از تحلیل واریانس یک طرفه استفاده کنم، میشه بگین چطوری؟
شما که نوشتید استقلال جزو شرایط این آزمون هست، پس چطوری با این آزمون شرط استقلال سنجیده میشه؟!!!
سلام کاملا اشتباه گفتند. انتخاب آزمون که اینجوری نیست. آزمون استقلال یک آزمون رابطه سنجی اما تحلیل واریانس یک آزمون تفاوت سنجی . یعنی دو دنیا حتی دو رشته تحصیلی مختلف در آمار. ارتباطی به هم ندارند. آموزش آزمون استقلال عزیزم 8 ساعت زمان می خواد
با سلام و احسنت به شما
عالی بود مطالب و ممنون میشم مطالب اضافی تر در مورد انتخاب آزمون های تعقیقبی با توجه به شرایط مختلف رو بگید.
سلام ممنونم. عزیزم هست مطلب کامل در موردش. در سایت آکادمی سرچ کنید
سلام خسته نباشید
من ازمون ANOVA رو برای مقایسه میانگین نمره کلی متغیرم در سه بیمارستان انجام دادم
و پی ولیو نشان داد که اختلاف معنا داری وجود دارد
بین گروهای مختلف هم انجام دادم و بین دو گروه اخالاف معنا دار وجود داشت
حالا برای اینکه این جداول رو در پایان نامم منعکس کنم باید چطوری بیارم؟
استادم گفتن جدول خامش بدردمون نمیخوره
باید جدول به این صورت باشه که یک سمتش میانگین ها و در سمت دیگر پی ولیو باشه
ممنون میشم راهنمایی کنید
عزیزم در کلاس آموزش کامل نوشتن فصل 4 اون داده شده. 15 تا 20 صفحه است این نکات با نوشتن در جمله نمیشه گفت