 آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی
آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی

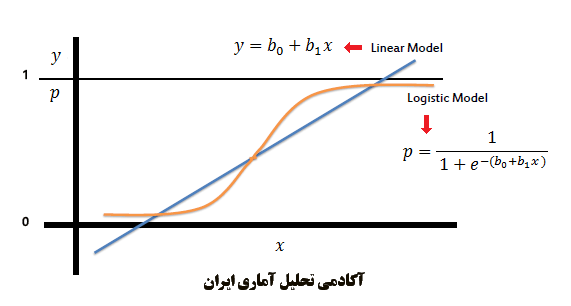
همانطور که می دانیم ، برای انجام تحلیل رگرسیون خطی متغییر وابسته باید کمی و در سطح سنجش فاصله ای/نسبی باشد. اما گاهی اوقات اتفاق می افتد که متغییر وابسته تحقیق در مقیاس فاصله ای/نسبی نبوده و مقیاس آن به صورت اسمی( دووجهی یا چندوجهی) است. یکی از سوالات شرکت کنندگان در دوره های کاربردی SPSS آکادمی تحلیل آماری شرکت می کنند این است که در چنین حالتی با توجه به اینکه پیش فرض اساسی تحلیل رگرسیون مقیاس فاصله ای /نسبی متغییر وابسته است چه باید کرد. در چنین حالتی نرم افزارهای آماری این امکان را برای ما فراهم نموده اند تا بتوانیم عوامل پیش بینی کننده تغییرات یک متغییر اسمی را نیز شناسایی کنیم. این روش، که رگرسیون لجستیک نام دارد در اواخر دهه 1960 و اوایل دهه 1970 به عنوان بدیلی برای روش رگرسیون خطی و همچنین تابع تشخیصی مطرح شد. زمانی که متغییر وابسته در سطح اسمی است و متغییرهای مستقل هم ترتیبی و هم فاصله ای هستند روش های رگرسیون خطی معمولی و تحلیل تشخیصی مقدار برآورد را کمتر از مقدار واقعی نشان می دهند.
رگرسیون لجستیک شبیه رگرسیون خطی است با این تفاوت که نحوه محاسبه ضرایب در این دو روش یکسان نمی باشد. بدین معنی که رگرسیون لجستیک به جای حداقل کردن مجذور خطاها احتمالی را که یک واقعه رخ می دهد حداکثر می کند همچنین در تحلیل رگرسیون خطی همانطور که در دوره های آکادمی تحلیل آماری ایران به آن اشاره می شود برای آزمون برازش مدل و معنی دار بودن اثر هر متغییر در مدل به ترتیب از آماره های F و T استفاده می شود در حالی که در رگرسیون لجستیک از آماره های کای اسکوئر و والد استفاده می شود.
رگرسیون لجستیک نسبت به تحلیل تشخیصی نیز ارجحیت دارد و مهمترین دلیل آن است که در تحلیل تشخیصی گاهی اوقات احتمال وقوع یک پدیده خارج از طیف صفر تا یک قرار می گیرد و متغییرهای پیش بین نیز باید دارای توزیع نرمال چند متغییره باشند در حالی که در رگرسیون لجستیک، احتمال وقوع یک پدیده در داخل محدوده صفر تا یک قرار دارد و رعایت پیش فرض نرمال بودن متغییرهای پیش بین لازم نیست.



