می 8, 2016
آموزشی, تجزیه و تحلیل اطلاعات
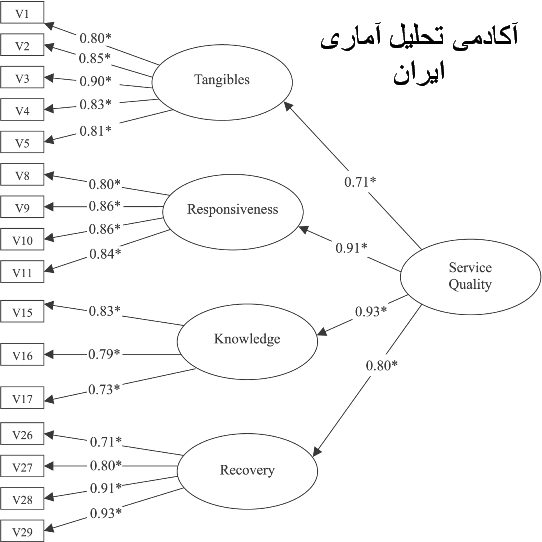
تاریخچه تحلیل عاملی نخستین کار درباره تحلیل عاملی حدود ۱۰۰ سال پیش توسط روانشناسی به نام چارلز اسپیرمن صورت گرفت، که به گونه کلی پدر این روش شناخته شده است و در سال ۱۹۲۷ توسط خود او توسعه یافت. بعد از او کارل پیرسون، روش مولفه های اصلی را پیشنهاد …
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
می 3, 2016
آموزشی, تجزیه و تحلیل اطلاعات
شبیه سازی امروزه، شبیه سازی به عنوان یکی از مهم ترین ابزار پژوهش در زمینه های مختلف علمی است. شبیه سازی به نوعی ساختن ماکت یا مدل عملیاتی است. در این مدل واقعیت ساده تر ارایه می شود و عناصری از واقعیت که در آن ارایه می شود، از پیچیدگی …
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
مارس 26, 2016
آمار و روش تحقیق, آموزشی, تجزیه و تحلیل اطلاعات
رگرسیون رابطه نزدیکی با همبستگی دارد بدین معنا که برای انجام رگرسیون باید ضریب همبستگی را محاسبه کرد.اگر میان متغییرهای مورد مطالعه همبستگی وجود داشته باشد تنها در این صورت است که می توانیم از رگرسیون برای آزمون فرضیه های پژوهش استفاده کنیم.هر چه همبستگی میان متغییرها قوی تر باشد تخمین نیز قوی تر است.فرق رگرسیون با ضریب همبستگی در آن است که ما در رگرسیون تبیین و تخمین می کنیم ولی در ضریب همبستگی تنها میزان هم تغییری متغییرها را بررسی میکنیم.
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
مارس 20, 2016
آمار و روش تحقیق, آموزشی, تجزیه و تحلیل اطلاعات
ضریب همبستگی رتبه ای کندال حالت تقارن دارد زیرا دو متغیری که قرار است همبستگی بین آنها مشخص شود، مهم نیست که کدامیک متغییر مستقل و کدامیک متغییر وابسته است.
ضریب همبستگی رتبه ای کندال مشخص می کند تا چه میزان افزایش یا کاهش در یک متغییر با افزایش یا کاهش در متغییر دیگر همراه است.
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
مارس 20, 2016
آمار و روش تحقیق, آموزشی, تجزیه و تحلیل اطلاعات
همبستگی پیرسون ، همبستگی پارامتری است که آن را با rp نشان می دهند.
ارتباط خطی بین دو متغییر که یکی متغییر مستقل و دیگری متغییر وابسته است را نشان می دهد. به عبارت دیگر ضریب همبستگی پیرسون یک شاخص متقارن است. یعنی متغییر وابسته را می توان بر مبنای متغییر مستقل و متغییر مستقل را می توان بر مبنای متغییر وابسته محاسبه کرد که نتایج هر دو حالت، یکی است.
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
مارس 11, 2016
آمار و روش تحقیق, آموزشی, تجزیه و تحلیل اطلاعات
برای استفاده از آزمونهای غیرپارامتری شرایط کلی زیر مورد توجه است:
داده های یا متغییر مورد مطالعه، دارای سطح اندازه گیری کیفی و به صورت اسمی و رتبه ای می باشند.
توزیع داده ها در جامعه آماری، از توزیع نرمال پیروی نمی کند.
در پژوهشی که شیوه نمونه گیری غیر احتمالی باشد، از آزمونهای غیرپارامتری استفاده می شود.
در آزمونهای غیرپارامتری، میانه یک یا چند متغییر را در یک یا چند گروه مقایسه می کنند.
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
ژانویه 22, 2016
آمار و روش تحقیق, آموزشی, تجزیه و تحلیل اطلاعات
آمار پارامتریک که در خلال جنگ جهانی دوم شکل گرفت در برابر آمار ناپارامتریک قرار می گیرد.از تقسیم بندیهای رایج آمار، تقسیم بندی آن به آمار پارامتریک و ناپارامتریک است. به سادهترین بيان بايد گفت كه براي سنجش فرضيه هايي كه متغير آن كمي اند، از آمار پارامتريك استفاده ميشود. متغيرهاي كمي به علت كمي بودن و واحد پذير بودن از اين ويژگي برخوردارند كه آنها را ميانگينپذير و انحراف معيارپذير ميكنند و به دليل همين ويژگي معمولا براي استفاده از آزمون هاي پارامتريك، پيش فرض هايي لازم است كه از جمله، نرمال بودن توزيع جامعه است زيرا در حالتي كه توزيع جامعه نرمال نباشد، ميانگين و انحراف معيار، نمايي واقعي از داده ها را به تصوير نميكشانند.
توضیحات بیشتر »
با دوستانتان به اشتراک بگذارید
 آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی
آکادمی تحلیل آماری ایران مدرسه پژوهش کمی و کیفی